
The world is producing, and storing, ever more data. Scientists, engineers, businesses; small and large are all engaged in an ever escalating race to measure, record and gain insight from all aspects of their processes.
The need for data compression has been known for many years. Traditional compression algorithms, such as those used by Tar or Zip, will be familiar to many. Two major approaches are used, lossless and lossy compression.
Lossless compression achieves a reduction in file size, without discarding any information, by exploiting the statistical properties of input files. Zip is an example of a lossless compression algorithm, the files you put in a zip come back out completely unchanged. This seems great, but lossless compression can only compress a file so much.
To achieve better file size reductions, lossy compression can be used. In lossy compression, information is strategically thrown away or modified to reduce the amount of data needing to be stored. This style of compression will be familiar from day to day life - think: pixelated images, MP3 files or blocky streamed video.
Lossy compression achieves greater data reduction but there is a hidden caveat. For example, MP3 compression attempts to throw away inaudible components of audio, affecting the listeners' experience as little as possible. This works great for music but could it work on a photo where there is no audio? This is the trade off - lossy compression needs advance knowledge of and tailoring to specific inputs, something it can be challenging to have in scientific and engineering research.
How can this gap be crossed? How can we achieve the compression rates of highly tailored lossy compression algorithms like MP3, but on arbitrary data about which we might not know much? Researchers are investigating the use of AI in this area, training models to recognise their data files and design a compression algorithm without human input.
Baler
Researchers from the University of Manchester (PI: Marta Camps Santasmasas) and Lund University, Sweden (project manager: Alexander Ekman) have created Baler which allows users to use lossy compression on arbitrary data, creating an application which can learn about datasets and obtain a method for compression and decompression.
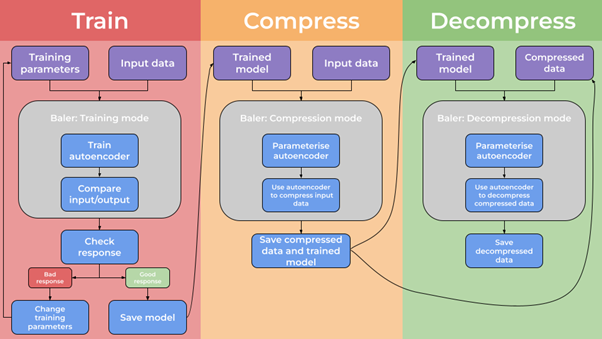
Train: In this mode, the user provides some input parameters and the data they want to compress. Baler learns about this input data and produces a trained 'model'
Compress: In this mode, Baler uses the trained model to compress the data and writes out compressed version of the input files
Decompress: In this mode, Baler takes previously compressed files and re-expands them using the trained model
Autoencoder
So, what is this trained model which has been mentioned a few times? The model is the saved state of the AI training. In Baler's case, this takes the form of an autoencoder, a specific type of neural network which is trained to decrease the number of dimensions of the input data, making it smaller.
The diagram below shows how an autoencoder works. With each layer of learning, the number of nodes used to describe the data decreases. By running the input data through the model, and evaluating the difference between the input and output each time, the network is trained. Once trained, the encoder half can be used individually to perform compression and save a compressed file. At a later time, the decoder half can be used to decompress the compressed file into the original form of the input data.
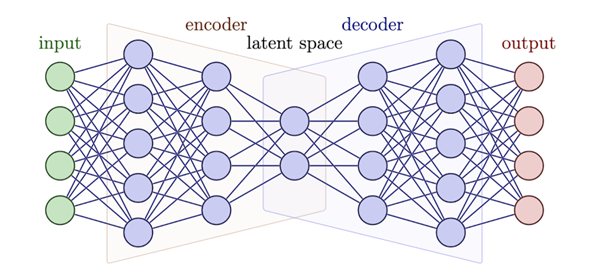
- Input: Data to compress
- Encoder: A series of linked nodes, decreasing in number of dimensions
- Latent space: The compressed data
- Decoder: A network of nodes, expanding in number of dimensions
- Output: Decompressed files
Baler in Action
Baler has been applied to a few fields, including Computational Fluid Dynamics, a highly data intensive discipline. Below is an example of Baler compressing and decompressing a frame from a CFD simulation.
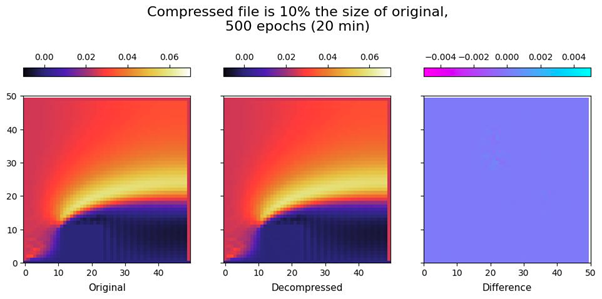
Here, good compression and decompression has been achieved, with a good reduction in stored file size while retaining a good representation of the input data.
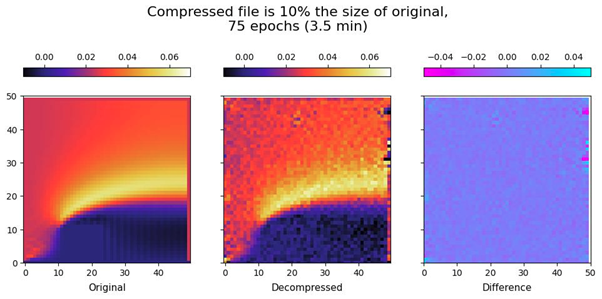
However, there is a cost, training time. With less training the reproduction of the input is much less good (see below).
The Research IT Contribution
Research IT was approached by the Baler developers to provide an Research Software Engineer (RSE) to help grow the project from a Master's student project into a product ready for research use. The original request asked for an RSE to extend Baler to enable support for GPU processing and to select and carry out packaging of the application for easy distribution and use.
Oliver Woolland was assigned to the project and supported the development of Baler providing consultancy and advice on the overall approach of Baler, as well as writing new features, enhancements to the code and solving issues.
Oliver led the adoption of more robust package management for Baler's dependencies and packaging the application as a Docker container. Baler's packaging as a Docker container brought many benefits to the project. It allowed Baler to be distributed more easily and reproducibly, without requiring obtaining the Baler source code and without the need to set up a specific environment for the software to run in.
Furthermore, Oliver refactored significant portions of the Baler codebase to allow the use of GPU acceleration achieving high speed ups when used on well equipped machines.
These contributions came together when the Baler containers were used to trivially deploy Baler to several GPU equipped computing clusters. This allowed Baler to move between development and production seamlessly.
Conclusion
Baler is now an open source project and can be found on Github and on the Dockerhub. There is also a paper giving more details on the method and early results. The project aims to continue to grow, taking on students from the Google Summer of Code and actively seeking and encouraging contributions to the open source codebase. It is hoped that Baler will continue to find new users and new applications and help take on the world's big data challenges.
Contact Us
If you would like a Research Software Engineer to work with your research team and supply software development expertise, then please get in touch through our email address.
The group currently consists of nearly 40 research software engineers with a wide range of technical skills in many areas of expertise including web development, mobile app development, data science and scientific computing. RSEs are available for varying lengths of time, and days per week to suit your research needs. We currently have a lead time of between 3-9 months depending on what you require so please engage with us as early as you can to give us the best chance of being able to help you.